2015-01-08
I see this question a lot on the forums: “how do I optimize SSIS for bulk insert
operations?” It might be asked in some
roundabout ways:
·
Why does it take so long to load this file?
·
How can I load data faster to Azure?
·
How do I insert millions of rows efficiently?
·
What flags should I set on the bulk insert task?
This post is going to cover the
basics of what every ETL developer should know about optimizing inserts. Let’s get a couple of things out of the way first,
though.
When should you use the Bulk Insert Task in SSIS?
That’s easy, never. You read that right, never. My colleague, Craig, advised me not speak in
absolutes, but this is a pretty safe one.
Here are the reasons why:
- Data flows are faster, as proven here.
- You cannot exclude columns without a format
file.
- If you use a format file, that’s one more
artifact to deploy, which increases complexity and risk
- Creating format files is really kooky and you
need to google the syntax every time you do it
- You cannot add columns (unless you use a format
file and default constraint – not very useful)
- You cannot transform columns in flight
- DATE data types are extremely fussy
- The target table includes the database name (the
way the SSIS Component works), which cripples portability to different
databases (unless you override this with an expression)
- They never go right the first time – seriously,
I have never gotten them right the first go
What should the dataflow look like before the insert component?
- It should have a source and very little else. In fact, it’s a really good idea to stage
your data before the insert.
- Do all the heavy cleansing and data manipulation
ahead of time. In this way you will not
tie up a connection with your destination, while you are busy manipulating the
data in the pipeline.
- Leverage the database for sort operations
- Eliminate blocking and partially blocking components
Getting Started on the Dataflow Task
The dataflow configuration is important, but it’s not
everything. Actually, much of the slowness
during a bulk insert is caused by what’s going on in the database. Database settings, indexes, constraints and
partitions must all be considered. We
are going to set up this task to get minimal logging which can tremendously
boost performance. I’ll performance
along the way using a 300 MB raw file (3.8 million rows, 500 bytes per row) to
insert into various versions of a table and various settings of the database
and SSIS. Let’s start with the database:
- Make sure the database is in Simple or Bulk
Logged recovery model
- Make sure that backups and other maintenance
tasks are not occurring during your ETL run
- Turn on Trace Flag 610 – this is done at the
server level as a start up parameter (applies only to clustered indexes)
The first two of these steps are absolutely necessary for minimal logging.
Heaps
Heaps are a great way for getting data inserted quickly and
in parallel. However, there are a few
considerations if this going to happen with minimal logging.
- There must be no indexes on the table at
all. Simply disabling them will not do
the trick.
- You must use the TABLOCK hint
- You can still parallel load a heap with the TABLOCK hint on. It will take a special
lock (BU) which is compatible with other BU locks.
This is how it performed with different settings on my local
machine:
Only the last two tests had minimal logging, with huge gains over the others. The last used a parallel loading approach taking advantage of the BU lock type for heaps. This is how that worked. Suppose we have a column, "id", that increments with each row in the source file. We can use a conditional split to separate these into 3 paths, i.e. “id % 3 == 0” as the first case expression, “id % 3 == 1” as the second and so on. All three destinations have TABLOCK on and will get an even distribution of rows:

Clustered Indexes are a different
animal and often come with additional issues – Foreign Keys and more indexes. We can still get minimal logging, but this
time it matters if there is already data in the table (unlike a heap). Parallel loading is not possible directly
into the table, but we can use partitioning to our advantage and load the data
into staging tables in parallel. Then we
can switch the data back together. It doesn't apply in all that many scenarios, so I am not going to test that one out. But here
are the basics considerations on the rest of things:
- Drop
indexes (when these are recreated they will be minimally logged – a much
faster operation all told, especially staging / partition switching scenario)
- Uncheck
the Check Constraints flag in the OLEDB destination (note that you will need to check
constraints after the table is loaded or they will not be trusted)
- Check constraints flag checks the Foreign keys
which can cause multiple sort operations as the keys get validated before
insert. I explained that here.
- If you do not have TF 610 turned on:
- Use the TABLOCK hint
- Use the ORDER hint (this takes the column names
of the clustered index). Note that the
incoming data must be in the order of the clustered index
- Make sure there are no rows in the table. Even a single row in the table will cause
full logging
- Insert all the rows in a single batch. If you do not, only the first batch will be
minimally logged. More on how to do that
in SSIS below.
- If you do have TF 610 turned on, then the hints
do not matter, but the data should still be in the order of the index. I have ignored this advice in testing, because I find that there are still performance gains from using the hints. The table can contain data and inserts do not
need to be in a single batch. Consequently, turning this flag on can usually
boost performance without code changes.
It should be tested, of course. J
- Compression causes extra overhead in order to
compress the data. If the table does not
truly need it, do not use compression as a reflex response in order to conserve
disk. In a staging table, it is not
worth the downstream benefit that you would gain on the reading side.
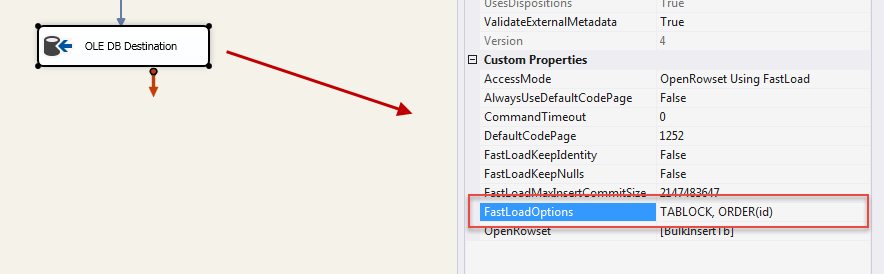
The Order hint is not exposed in
the editor of the OLEDB destination, but you can type it in, in the properties
window here:
SSIS has two parameters related to
batch size: Batch Size and Maximum
Insert Commit Size. Ignore the
first. In SSIS, if the max commit size
is greater than the buffer size, each buffer is committed. If you set this to 0, the whole result is
committed in a single batch. Note that
this could bloat the log so use this setting with caution. TF 610 can commit with smaller batches
because it does not care if rows exist.
This is how you should set it to get a single batch:
Here are
the performance results:
The take-aways:
- Minimal logging can give a huge performance
boost for bulk insert operations
- Use TF 610 if you are inserting into a CI and
there is data in the table. That test didn't have the best performance, but it was still better than many of the rows with no data.
- Use partition switching if each load can be for
a single partition and you cannot use TF 610
- Check constraints and recreate indexes
after the load
- Commit in a single batch where plausible
Reference
The Data Loading Performance Guide
Mark Wojciechowicz
Labels: SSIS